LLaMA-2
The LLaMA-2 model was introduced in the paper “LLaMA-2: open foundation and fine-tuned chat models” by Meta in Jul-2023. Similar to LLaMA-1, the LLaMA-2 model also applied pre-normalization using RMSNorm, use the SwiGLU activation function, and rotary positional embeddings. However, LLaMA-2 differs from LLaMA-1 in the following aspects:
- LLaMA-1 was trained on up to 1.4T tokens and has a context length of 2k. LLaMA-2 was trained on 2k tokens, and has a context length of 4k.
- Grouped-Query attention: A standard practice for autoregressive decoding is to cache the key (K) and value (V) pairs once they are computed for the previous tokens in the sequence, speeding up attention computations. However, caching the KV pairs require extra memory. Also, once the computations are sped up, reading and writing to and from the GPU memory becomes the bottleneck. Hence, LLaMA-2 leveraged the multi-query attention (MQA) approach.
Comparing the pretrained LLaMA-2-70B to other existing LLMs (GPT-3.5, GPT-4, PaLM, PaLM-2-L) on benchmark datasets (MMLU, TriviaQA, Natural Questions, GSM8K, HumanEval, BIG-Bench Hard), the performance of these LLMs are (from best to worst): GPT-4, PaLM-2-L, GPT-3.5, LLaMA-2, PaLM.
Cost of pre-training
The authors mentioned that they used A100-80GB for pre-training.
- The LLaMA-7B, 13B, 34B, 70B used 184K, 368K, 1038K, and 1720K GPU hours respectively.
- The current lowest cost on-demand pricing for the A100 is from Lambda labs, which cost \$1.10 per hour. So the 7B could costs around \$200K to pretrain, while the 70B costs around \$1.9M to pretrain.
Instruction Fine-tuning
The authors of LLaMA-2 kickstarted instruction fine-tuning by using publicly available data from the FLAN-PaLM work. However, they found that these aggregated third party datasets often have insufficient diversity and quality. Hence, the LLaMA-2 team internally collected a total of 27,540 annotations for instruction fine-tuning. During fine-tuning, the loss on tokens from the user prompt are zero-out, hence the model only learns from the response tokens.
RLHF (TODO)
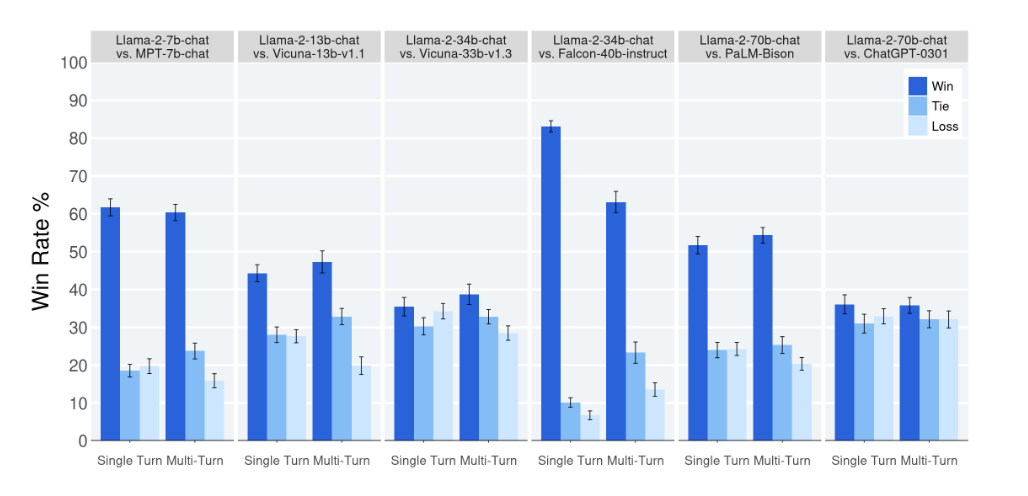
Evaluation
After performing instruction fine-tuning and RLHF, the authors evaluated the resultant LLAMA 2-CHAT models to various open-source and closed-source language models, by conducting human evaluation focusing on helpfulness and safety. For ChatGPT, the authors used gpt-3.5-turbo-0301. For PaLM, the authors used chat-bison-001. The following Figure show that the LLaMA 2-CHAT model is competitive with ChatGPT-3.5, and better than all other models.