
BERT
BERT uses just the encoder stack of the Transformer. It was described in the paper “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, published in October 2018. It showed that its bidirectional masked language modeling (MLM) pretraining objective allows for better downstream fine-tuning as compared to the autoregressive GPT-1.
Masked Language Modeling (MLM)
BERT uses the MLM as its pretraining objective. This randomly selects 15% of the input tokens to replace with a [MASK] token, replace with a random word, or kept as is. The model then needs to predict the original tokens for these selected tokens. Quoting an example used in the BERT paper, when given an input sentence “my dog is hairy”:
- 80% of the time: Replace the word with the
[MASK]token, e.g., “my dog is hairy” $\rightarrow$ “my dog is[MASK]”. - 10% of the time: Replace the word with a random word, e.g., “my dog is hairy” $\rightarrow$ “my dog is apple”
- 10% of the time: Keep the word unchanged, e.g., “my dog is hairy” $\rightarrow$ “my dog is hairy”.
Motivations of MLM
- Consider what might happen if BERT had only applied the strategy of replacing words with the
[MASK]token. Then, the model will only learn representations for[MASK]tokens. - Next, consider what might happen if BERT had only done masking and replacement with random words. Then, the model will learn that the correct word is always not equal to the given word.
- Thus, keeping some words unchanged (but asking BERT to predict those words nevertheless) is also crucial.
Using all three strategies in combination, the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to learn contextual representations for all input tokens.
Next Sentence Prediction
In addition to MLM, BERT also uses a next sentence prediction (NSP) task as part of its pretraining. The motivation is learn relations between a pair of sentences, enabling BERT to be better used for downstream NLP tasks such as Natural Language Inference (NLI a.k.a textual entailment) or question answering (QA).
During pretraining, BERT is fed two sentences as input (using [SEP] as a separator token). Half of the time, the second sentence is the true follow-on sentence, while the other half of the time, BERT is presented with a randomly sampled sentence.
Note that the NSP task has been found in follow-on work (e.g. RoBERTa) that it is not crucial for pretraining, and the community has largely focused on MLM as a pretraining objective.
Model Details and Input Representation
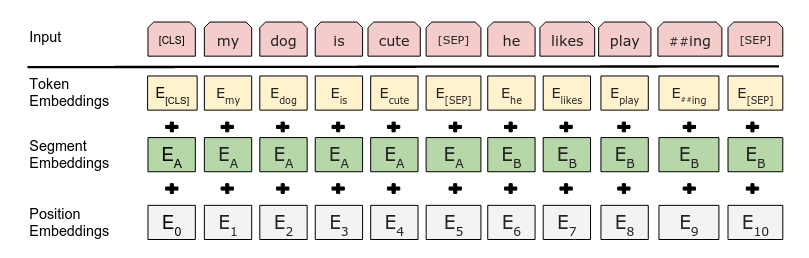
BERT uses the WordPiece subword tokenization with a 30K vocabulary.
The first token of every input sequence is always the special classification token [CLS].
The final hidden state corresponding to this token is used as the aggregate sequence representation for downstream classification tasks.
For pretraining, BERT uses the BooksCorpus (800M words) and English Wikipedia (2,500M words).
The BERT paper trained two model sizes:
- BERT-base: 110M parameters, 12 layers, 768 hidden dimensionality, 12 attention heads. This was chosen to be the same model size as GPT-1, for comparison purposes.
- BERT-large: 340M parameters, 24 layers, 1024 hidden dimensionality, 16 attention heads.
The other hyper-parameters are: 256 sequence length, 512 batch size, Adam as optimizer, Dropout of 0.1, and GeLU (Gaussian Error Linear Unit) as activation function.
Fine-Tuning for Downstream Tasks and Evaluation
In experiments, the BERT paper showed that it obtained better downstream fine-tuned performance on various NLP benchmark datasets, as compared to GPT-1, and an in-house autoregressive (left-to-right) model.
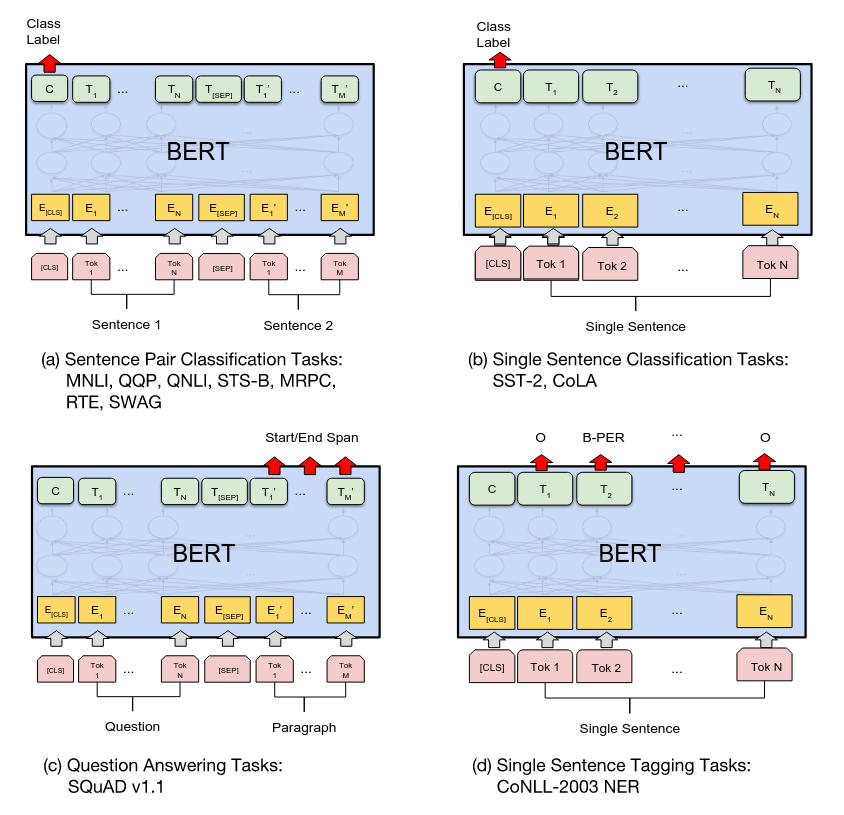
To fine-tune BERT on downstream NLP tasks, the authors put an additional header (classification) layer on top of BERT. As shown in the above Figure, the BERT paper performed fine-tuning experiments on four types of tasks:
- (a) and (b) are sequence level tasks, where the
[CLS]representation is fed to a classification layer. - (c) and (d) are token level tasks, where the hidden representations (from the final layer) are individually fed to a classification layer for per-token predictions.
