
UL2 - Mixture of Denoisers for Pretraining
The UL2 encoder-decoder model with a mixture of denoising objectives, was introduced in the paper “UL2: Unifying Language Learning Paradigms” from Google, published in May 2022. The aim of UL2 is to pretrain a model so that it works better than the autoregressive GPT-like models and the encoder-decoder T5 models, across many different NLP tasks. In evaluations, UL2 20B performs better than GPT-3 175B and T5 11B, but still lags behind the large PaLM 540B model.
The UL2 authors did not consider comparing with encoder-only BERT style models, as they mentioned that these class of models (i) are very restrictive in generation capabilities, (ii) task specific classification heads needs to be employed for downstream tasks. Hence, they focused on comparing with:
- Decoder models: The input is concatenated with the target, and their representations are concurrently built layer by layer up the Transformer network.
- Encoder-decoder models: These are models that process input tokens and target tokens independently with a different set of parameters. There is a cross attention component where the decoder attends to the final encoder representations of the input tokens.
Mixture of Denoisers as PreTraining Objective
The authors defined three paradigms of denoising:
- R-Denoiser: this Regular denoising is the standard span corruption introduced in T5. These spans are short and are more useful to acquire knowledge instead of learning to generate fluent text.
- S-Denoiser: the inputs and targets observe a Sequential order. This is akin to Prefix-LM where the context (prefix) retains a bidirectional receptive field.
- X-Denoiser: This is an eXtreme form of denoising where the model must recover a large part of the input. The authors used an aggressive denoising where approximately 50% of the input sequence is masked, either by masking very long spans (e.g. $\ge$ 12 tokens) or a high corruption rate (e.g. $\ge$ 30%).

The Figure above illustrates the different denoising approaches. Greyed out recectangles are masked tokens. The authors used a final objective that is a mixture of 7 denoisers from the above three different denoising paradigms.
Evaluation
The authors performed two main experiments:
- Evaluation of Pretraining Objectives: First, they compared their proposed “mixture of denoisers” pretraining objective, against the commonly used pretraining objectives.
- Evaluation at 20B scale: Then, they took their best performing architecture and trained a 20B parameters model. They evaluated this on a large set of 50+ NLP datasets, showing that they achieved SOTA results on a majority of the datasets.
Evaluation of Pretraining Objectives
The paper performed experiments using a UL2 decoder and UL2 encoder-decoder architecture, and compared with the following pre-training baselines:
- Causal Languge Model (CLM): the standard autoregressive language model used in GPT.
- Prefix LM (PLM): the prefix has bidirectional receptive fields, and the loss is computed on the targets.
- Span Corruption (SC): this is the span denoising used in T5, with a mean span length of 3, and denoising rate of 15%.
- Span Corruption + LM (SCLM): use a mixture of CLM and Span Corruption with an equal mix ratio.
- UniLM (ULM): this objective was proposed in Dong et al. (2019) which used a mixture of causal languge modeling, Prefix LM, and bidirectional denoising.
The authors evaluated on SuperGLUE and 3 datasets (XSUM summarization, TOT table-to-text generation, SGD schema guided dialog) from the GEM benchmark. For the UL2 model, they used a base architecture of 167M parameters decoder model, and 335M parameters encoder-decoder model.
The authors present two sets of results:
- The first Table below shows relative percentage improvements over using the SC as a baseline (note the SC* row in the first Table).
- The second Table below shows relative percentage improvements over using the CLM as a baseline (note the CLM* row in the second Table).
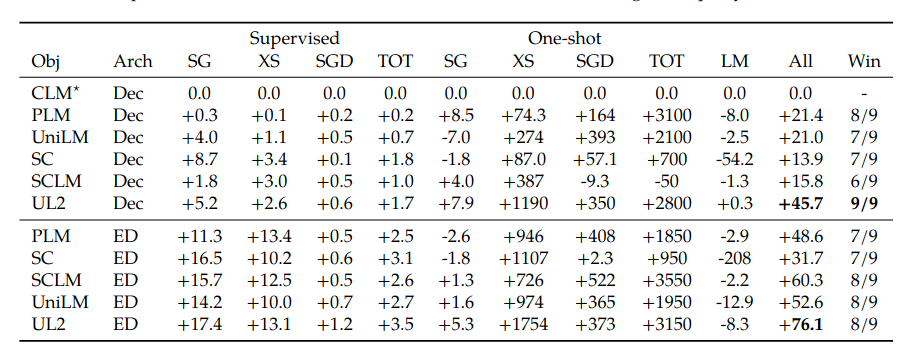
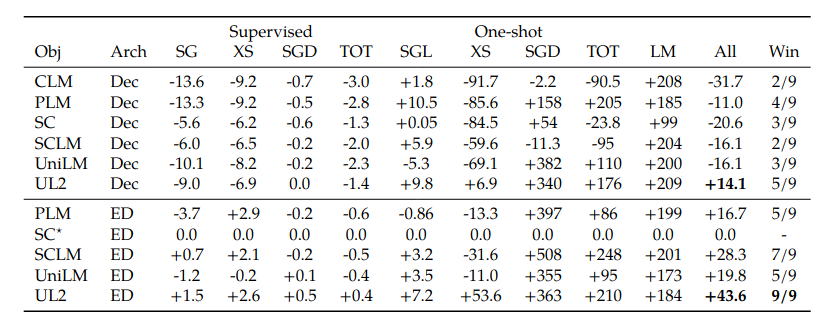
The abbreviations used in the table are: SuperGLUE (SC), XSUM summarization (XS), schema guided dialog (SGD), text-to-table generation (TOT), perplexity scores on C4 validation dataset (LM), equal weighted average score across all tasks (All).
The summary is:
- Encoder-decoder should be preferred over decoder-only models.
- Besides the UL2 that the authors are proposing, the best decoder-only model is the Prefix-LM pre-training.
- The proposed UL2 performs better than GPT-like (CLM) objective, and T5-like (SC) objective.
Evaluation at 20B Scale
Using their UL2 pretraining objective with an encoder-decoder architecture, the authors built a 20B parameters model. This model has 32 encoder layers, 32 decoder layers, and hidden dimensionality of 4096. It was trained on 1T tokens of the C4 corpus, using batch size of 1024.
Fine tuning experiments: The authors fine-tuned on a per-task basis (single of a single multi-task fine-tuning run). The authors used a set of 50+ NLP datasets that includes tasks on language generation, language understanding, classification, QA, commonsense reasoning, long range reasoning, structured knowledge grounding, and information retrieval. UL2 achieves SOTA on most of these datasets. Then on the SuperGLUE dataset, UL2 20B (90.7 average score) performs better than PaLM 62B (89.2 score) and T5 11B (89.9 score), but lost to PaLM 540B (92.6 score).
One-shot experiments: Performing one-shot summarization on the XSUM dataset, UL2 20B (65.2 average score) is better than GPT-3 175B (61.2 score), T5-XXL 11B (52.5 score), but it lost to PaLM 540B (78.8 score).
