
T5 Encoder-Decoder Language Model
The T5 (Text-to-Text Transfer Transformer) model from Google is introduced in the paper “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”, published in October 2019.
T5 is a text-to-text (encoder-decoder) Transformer architecture that achieves good results on both generative and classification tasks. The largest T5 model (11B parameters) achieves SOTA performance in 18 out of 24 NLP tasks.
Overview of Model
T5 casts all NLP tasks into “text-to-text” format, which provides a consistent training objective for both pre-training and fine-tuning. The model is trained with a maximum likelihood objective.
Task Specific Text Prefix
To specify which NLP task the model should perform, T5 adds a task specific (text) prefix to the original input sequence before feeding to the model (the authors note that changing the exact wording of the prefix had limited impact).
Following is a Figure extracted from the T5 paper that illustrates the text-to-text (input text, output text) format of T5 being applied on a few different NLP tasks:
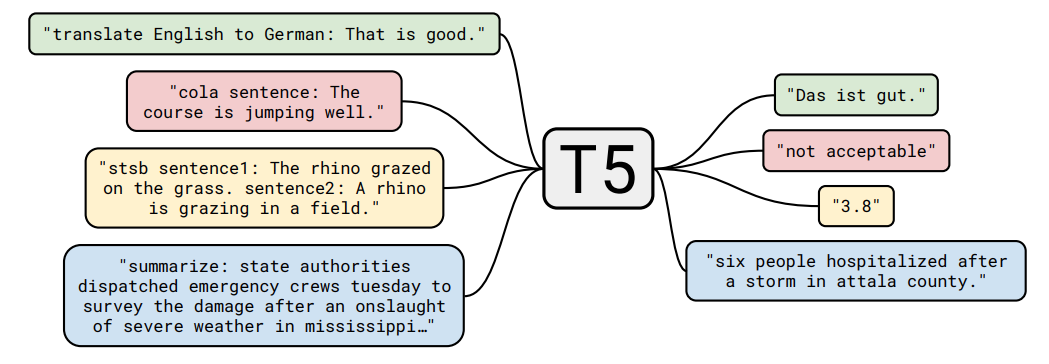
As an example, when given an example training example to translate “That is good” to target “Das ist gut”:
- The example is first transformed to: “translate English to German: That is good. target: Das ist gut”.
- Then train the model on next word prediction but focusing the loss on the target text portion.
- To perform inference, supply the prefix “translate English to German: That is good. target:” and ask the model to generate autoregressively. This approach was similarly used in GPT-2 in zero-shot experiments.
Span Corruption and Prediction
As the unsupervised pretraining objective, BERT had shown that pretraining with “denoising” objectives i.e. masked language modeling (MLM) vs auto-regressive language modeling, enables better transfer learning (fine-tuning) performance for downstream tasks.
The T5 model applies MLM with a slight twist (illustrated in the following Figure):
- It could mask individual tokens or token spans.
- It only predicts dropped-out tokens, to reduce computational cost of pre-training.

Baseline Model
The T5 encoder-decoder Transformer model closely follows its original proposed form in the “Attention is All You Need” Transformer paper, except for a few modifications: the layer norm bias is omitted, the layer normalization is placed outside the residual path, and T5 uses a different position embedding scheme.
The authors performed multiple experiments to try out different settings, using a baseline T5 model that is similar to size to BERT-base:
- This baseline model has both encoder and decoder stacks (each with 12 transformer blocks), uses 12 attention heads (each attention head is 64 dimensionality), hidden dimensionality is 768, sequence length is 512
- The feed-forward layer comprises (i) a dense layer with 3072 output dimension, (ii) ReLU activation, (iii) then another dense layer.
- In total, baseline T5 has 220M parameters, which is double that of BERT-base (since BERT has just an encoder stack). Finally, it used SentencePiece to encode text as WordPiece tokens.
Since all tasks are formulated as text-to-text, training objective is using maximum likelihood with cross-entropy loss. A test time, generation is done using greedy decoding, i.e. choosing the highest probability logit at every decoding timestep.
Explorations of Training Strategies
As pre-training data, the T5 paper built the “Colossal Clean Crawled Corpus” (C4) corpus, which consists of 750GB of clean English web text. This is filtered from the Common Crawl, which is a web archive that removes markup and non-text content from scraped HTML files, producing 20TB of text data each month.
Using the baseline model above, the T5 paper then performed various experiments on multiple NLP datasets (GLUE, SuperGLUE, CNN/Daily mail abstractive summarization, SQuAD, WMT English to various languages) to explore different training strategies, which we briefly describe in this Section.
MLM Strategies
The T5 authors experimented with different Masked Language Modeling (MLM) strategies:
- The MLM pre-training of BERT includes a random token swapping step. The T5 authors dropped this token swapping step. Instead, they simply randomly replaced 15% of the tokens with a mask token, and the model is trained to reconstruct the original uncorrupted sequence.
- In BERT, the pre-training aims ot predict the entire uncorrupted span. To improve pre-training efficiency, the T5 authors modified the target sequence to be just the concatenation of corrupted spans, e.g. “<X> for inviting <Y> last <Z>”. This makes the target sequence shorter, hence decreasing training time. This approach was also found to perform marginally better in evaluations.
Token corruption rates
The authors also tried out different token corruption rates: 10%, 15%, 25%, 50%. They found that using a corruption rate of 15% (also used by BERT) is the best.
Corrupting Spans
The usual MLM pre-training strategy is to make i.i.d. decision for each input token (to corrupt or not) and then replace with corrupted token with individual masks. The T5 authors experimented with using a single unique mask token to replace multiple consecutive corrupted tokens.
The advantage of replacing entire spans with a single token results in the unlabeled data being processed into shorter sequences. The disadvantage is that, in practice, if an insignificant number of corrupted tokens appear consecutively together, then span replacement behaves very similar to the usual token replacement strategy. Thus, the T5 authors specifically try to increase the number of corrupted spans. E.g. Given a sequence of 500 tokens, the authors might specify 15% of the tokens to be corrupted to yield a resultant 25 corrupted spans. Then, the average corrupted span length would be $= \frac{0.15*500}{25} = 3$.
Fine-Tuning Strategies
The authors compared the following three fine-tuning strategies:
- Fine-tune all parameters on a downstream task (this performs the best in their experiments).
- Introduce and only fine-tune adapter layers. These are additional dense-ReLU-dense blocks that are added after each of the existing feed-forward layers of each transformer block.
- Gradual unfreezing. I.e. start with only fine-tuning the final layer, then add second-to-last layer for fine-tuning, and so on, until all layers are fine-tuned.
Multi-Task Learning
The usual approach is pre-training a language model, followed by fine-tuning on specific datasets. The T5 authors also tried multi-task learning by simply mixing NLP datasets together, i.e. the denoised unlabeled dataset and the downstream NLP tasks datasets. Datasets have different sizes, so they sampled examples from each “task” with some probability when mixing. Overall, multi-task training slightly underperforms pre-training followed by fine-tuning on most tasks.
Model Scaling Strategies
- The authors explored different ways to scale their model 4x: number of training steps used for pre-training and fine-tuning (training steps), increase batch-size, increase number of parameters in model (model-size).
- The combinations they tried were: (1x size 4x training-steps), (1x size, 4x batch-size), (2x size, 2x training-steps), (4x model-size, 1x training-steps).
- They found that (2x model-size, 2x training-steps) and (4x model-size, 1x training-steps) perform well in experiments.
Final T5 Model Configuration
From the experiments above, the final T5 model is configured as follows:
- Pre-training objective: span corruption with mean length of 3, and corrupt 15% of the original sequence. Predict only the corrupted tokens/spans instead of the entire original sequence.
- Longer training is beneficial: batch size 2048 on sequences of 512 length, pre-train for 1 million steps. This means that T5 was pre-trained on 1 trillion tokens.
- Different model sizes: Base (220M), Small (60M), Large (770M), 3B, 11B (24 layers encoder and decoder, 128-headed attention).
- Multi-task pre-training on a mixture of unsupervised and supervised tasks.
- Beam search with width of 4.
The largest T5 model (11B parameters) using the above configuration achieves SOTA or is better than SOTA in various benchmark datasets: GLUE, SuperGLUE, SQuAD, CNN/Daily-Mail.
