
SWITCH - Sparsely Activated Encoder-Decoder Language Model
The SWITCH model was described in the paper “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”, published in January 2021. It is a sparsely activated expert model, i.e. activating a subset of the NN weights for each incoming example. The authors claimed this simplifies and improves over the Mixture of Experts (MoE) architecture.
Comparison with T5 Base
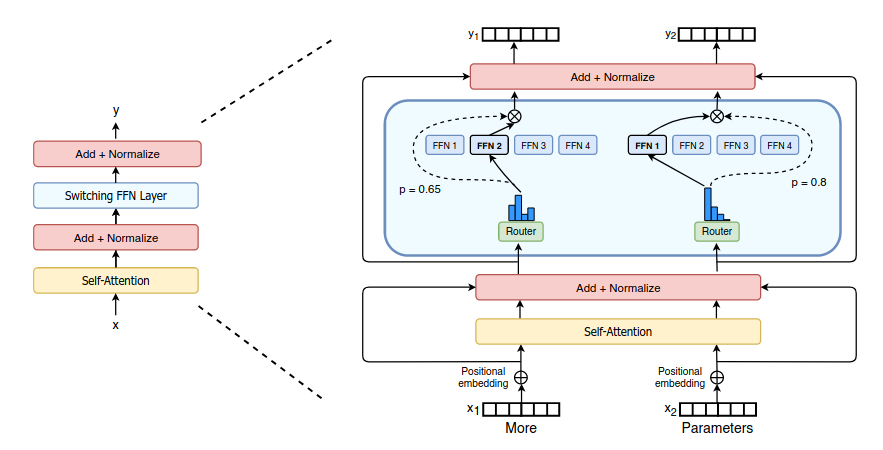
- The SWITCH Transformer model uses a sparse T5 encoder-decoder architecure, where the original dense FFN is replaced with a sparse Switch FFN layer.
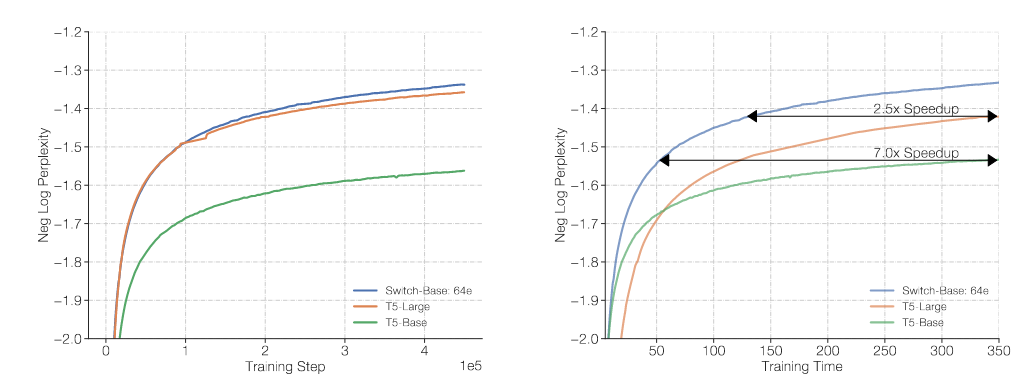
- The authors show that SWITCH transformers are more sample efficient, achieving the same levels of perplexity 2.5x quicker when compared with T5-Base which has the same amount of computations.
- However, although the SWITCH-Base is more sample efficient than T5-Base, and also performs better than T5-Base in fine-tuning experiments, but the SWITCH-Base has 17x more parameters than T5-Base. When SWITCH-Base is distilled down (so there is a distillation process) to the same number of parameters as T5-Base, it is still better than T5-Base, but it lost most of its performance advantage.
Sparse Activation
We now compare and contrast between MoE routing, vs SWITCH routing (proposed in this paper).
Mixture of Expert (MoE) routing
- Given input token representation $x$, MoE routes this to top-k experts $\tau$ out of N experts.
- The router variable $W_r$ produces logits $h(x) = W_r \cdot x$, which are normalized via a softmax over the N available experts at that layer: \(p_i(x) = \frac{e^{h(x)_i}}{\sum_{j}^N e^{h(x)_j}}\)
- The output of the layer is the linear combination of each expert’s computation $E_i(x)$ on the token, multiplied by the gate value $p_i(x)$: \(y = \sum_{i \in \tau} p_i(x) E_i(x)\)
Switch routing
- Route to only a single expert, referred to as a Switch layer.
- The SWITCH Transformer encoder block is illustrated below. The original dense FFN is replaced with a sparse Switch FFN layer (light blue). The Switch FFN layer returns the output of the selected FFN expert, multipled by the routher gate value (dotted line)
Evaluation
- SWITCH Transformers are more sample efficient when compared to the T5 transformer, achieving a lower loss with fewer training steps. SWITCH-Base is designed to use the same amount of computations as T5-Base:
- The authors designed FLOP matched SWITCH transformers: SWITCH-Base to match T5-Base, and SWITCH-Large to match T5-Large. On fine-tuning results, both SWITCH transformers out-perform their respective T5 models.
- But the SWITCH-Base has a total of 3800M parameters vs T5-Base which only has 223M parameters. The authors designed a distilled version of SWITCH-Base (to have 223M parameters, same as T5-Base), which is slightly out-performing T5-Base on SuperGLUE.
Written on February 20, 2023
