Parameter Efficient Fine Tuning (PEFT)
Assume that you want to fine-tune a large pretrained model for a number of different tasks. The traditional options are:
- Fine-tune the pretrained model on each task separately. But you will then be storing a separate copy of each fine-tuned model for each task.
- Assuming that the various tasks are not entirely different, then you can attempt to sort them in some linear order (e.g. in terms of increasing difficulty): fine-tune the model on task-1, then task-2, then task-3. But this runs the risk of catastrophic forgetting on earlier tasks.
Note however, that fine-tuning all parameters is impractical for very large models. Also, researchers had noted that SOTA models are massively over-parameterized, i.e. some parameters might be redundant. This observation enables PEFT to match performance of full fine-tuning.
PEFT using Pruning
One common PEFT method to induce sparsity is pruning. This can be done via applying a binary mask $\textbf{b} \in {0, 1}^{|\theta|}$ that selectively keeps or removes each weight on a model. The most common pruning criterion is using weight magnitute.
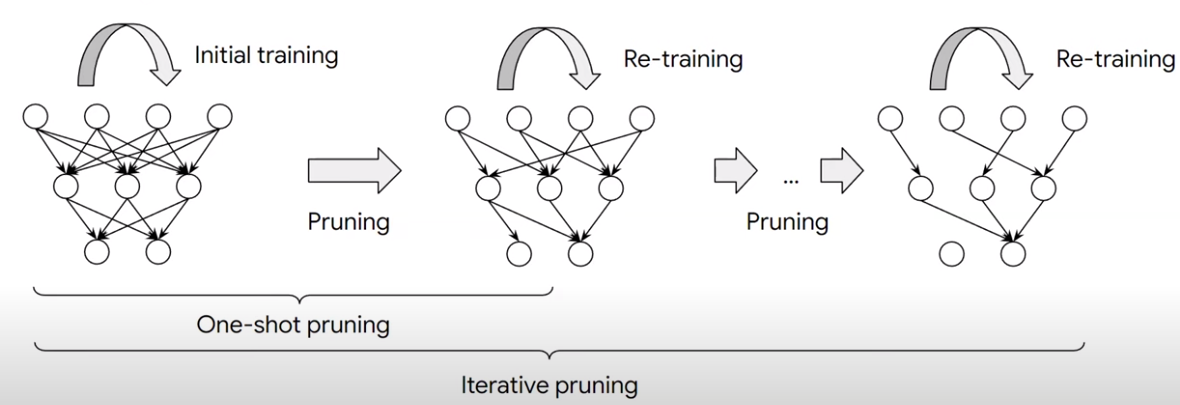
In the above, we start with an initially trained model. Then iteratively perform pruning (a fraction of the lowest magnitute weights are removed) and retraining on the non-pruned weights, until we reach a sparsity threshold.
PEFT using Adapter Modules
As a concrete examples, let’s assume that we are performing zero-shot cross-lingual transfer learning. The standard way to do this:
- Train a multilingual model, e.g. XLM-R
- Fine tune the above model on a task in a high resource (source) language
- Simply evaluate the model on a low-resource (target) language
The above process of fine-tuning the entire pretained multilingual model can achieve SOTA results. But due to the “curse of multlinguality” when training these multilingual models, when you initially increase the number of languages into the pre-training mix, the performance of the low resource languages initially improve (at some slight degradation of the high resource language). However, because the multilingual model is trying to distibute a fix limited budget of parameters across all these languages, as you keep on increasing the number of languages in the pre-training mix, there is a certain point where the performance across all languages start to degrade.
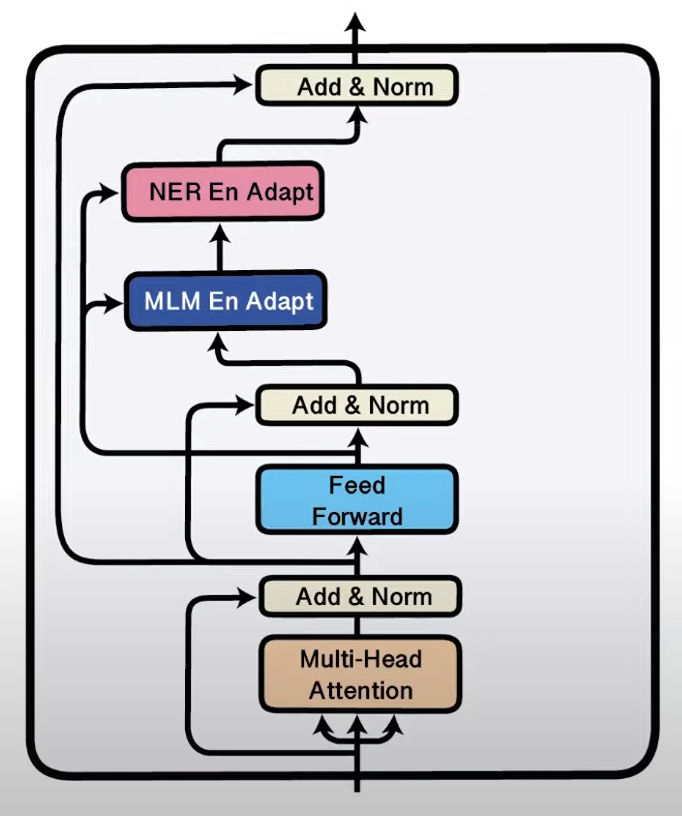
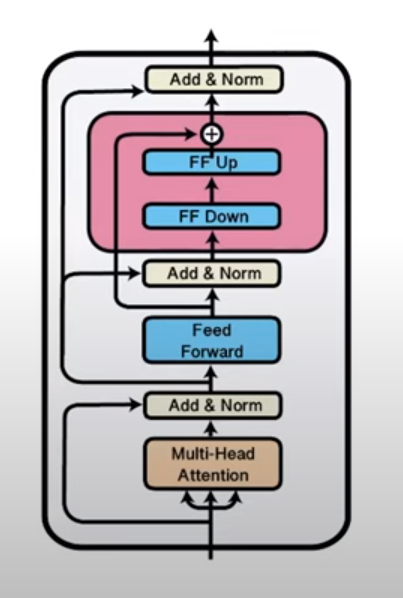
Alternatively, for a particular language that is already represented in the pretrained multilingual model, one could use language specific adapter, i.e. introduce an additional parameter module (shown in pink in the figure below) into the pretrained multilingual model. Then perform the usual masked language modeling (MLM) of this model on a text corpus of the target language: by keeping the original model weights fixed, and only updating the newly introduced adapter module.
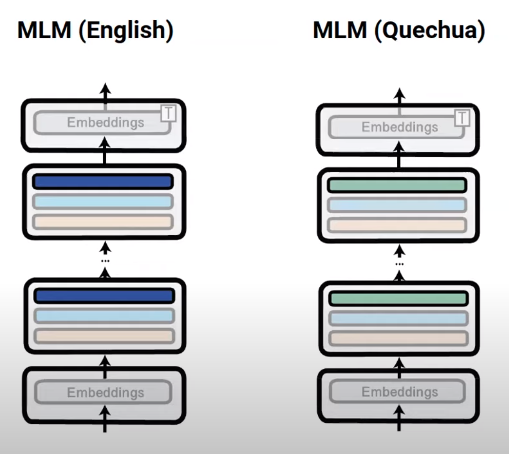
A case study is from the paper “MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer” (Pfeiffer et. al. 2020), which does multilingual named entity recognition (NER) by doing the following:
- Assume (high resource) source language is English, and (low resource) target language is Quechua. First train an English language adapter (the blue boxes in the figure below) using Wikipedia English texts. Then train a Quechua language adapter (the green boxes in the figure below) using Wikipedia Quechua texts.
- The weights of the base model is fixed. Only the weights of the adapter module are updated.
- It is important for both the source texts and target texts to come from a similar domain, for the task transfer step later on.
- Using language specific adapters allows better representation for the specific language within the multilingual space.
- We introduce a task adapter for the (high resource) source language (the pink module “NER En Adapt” in the right figure below). Now we train the model on English NER data, while keeping all weights fixed, except for the newly introduced task adapter. The idea here is that the “NER En Adapt” adapter module will learn language agnostic NER task knowledge.
- Zero-shot transfer to the target language. We now replace the source (English) language adapter, with the target (Quechua) language adapter, while keeping the “language agnostic” (NER) task adapter.
The following figures show training language specific adapters (left) and training task adapter for English (right).