
Multi-query and Grouped Multi-query Attention
Multi-query Attention
As illustrated in the following Figure, the speed of computation (FLOPs) in NVIDIA GPUs has increased at a faster pace than the memory bandwidth (GB/s), or speed of data tansfer between memory areas. This means that the bottleneck is in amount of data transfer in transformer operations, rather than number of computation operations. Hence, there is a need to reduce the memory requirements in transformer models, in order to reduce the need on the GPU to move tensors around.

The reduce memory requirements for self-attention, the technique Multi-query attention (MQA) was introdued in the paper “Fast Transformer Decoding: One Write-Head is All You Need” by Google in 2019. Here, the proposed method is to only have multi-attention heads for the query Q, while having a single attention-head for the key and value. The author showed that on a WMT14 English-to-German translation task with sequence length 128, the proposed MQA approach provided a 10-fold reduction in the inference/decoding time, while providing an acceptably small drop in performance.
Grouped Multi-query Attention
Grouped multi-query attention (GQA) was introduced in the paper “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints” by Google in EMNLP-2023. Here, instead of using just a single key-value head as was done in the multi-query attention (MQA), the authors formed query groups, and use a single key-value attention head for each query group.
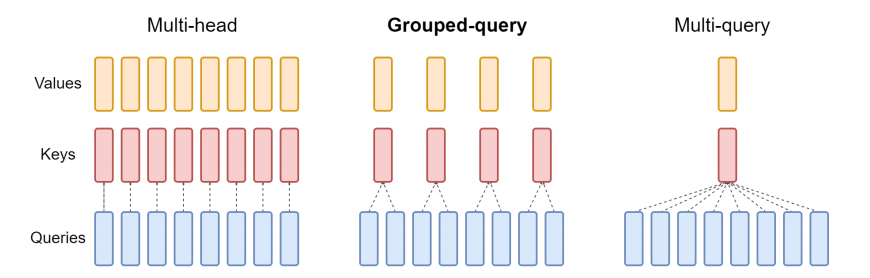
As illustrated in the above Figure:
- The usual multi-head attention has $H$ query, key, and value heads. I.e. there is a 1-to-1 correspondence between query, key, and value heads.
- The Multi-query attention introduced in the previous work shares a single key-value head across all query heads.
- The right-most Diagram shows that in this work, grouped-query attention shares a single key-value head for each group of query heads. This is thus an intermediate compromise between the two extremes of usual multi-head attention vs multi-query attention.
