
Key-Value Caching
At each time-step of a generative model, we just want to calculate the attention scores for the new token. To avoid re-calculating attention scores associated with previous (already generated) tokens, we apply Key-Value (KV) caching.
When is KV caching applicable?
- KV caching is applicable during generation steps in the decoder, i.e. in auto-regressive models such as GPT or the decoder part of encoder-decoder models like T5.
- Encoder-only models such as BERT do not generate tokens one after the other, and thus has no need for KV caching.
- KV caching is not applicable during fine-tuning, since there, you actually want the matrices to be updated during training.
KV Caching Illustration
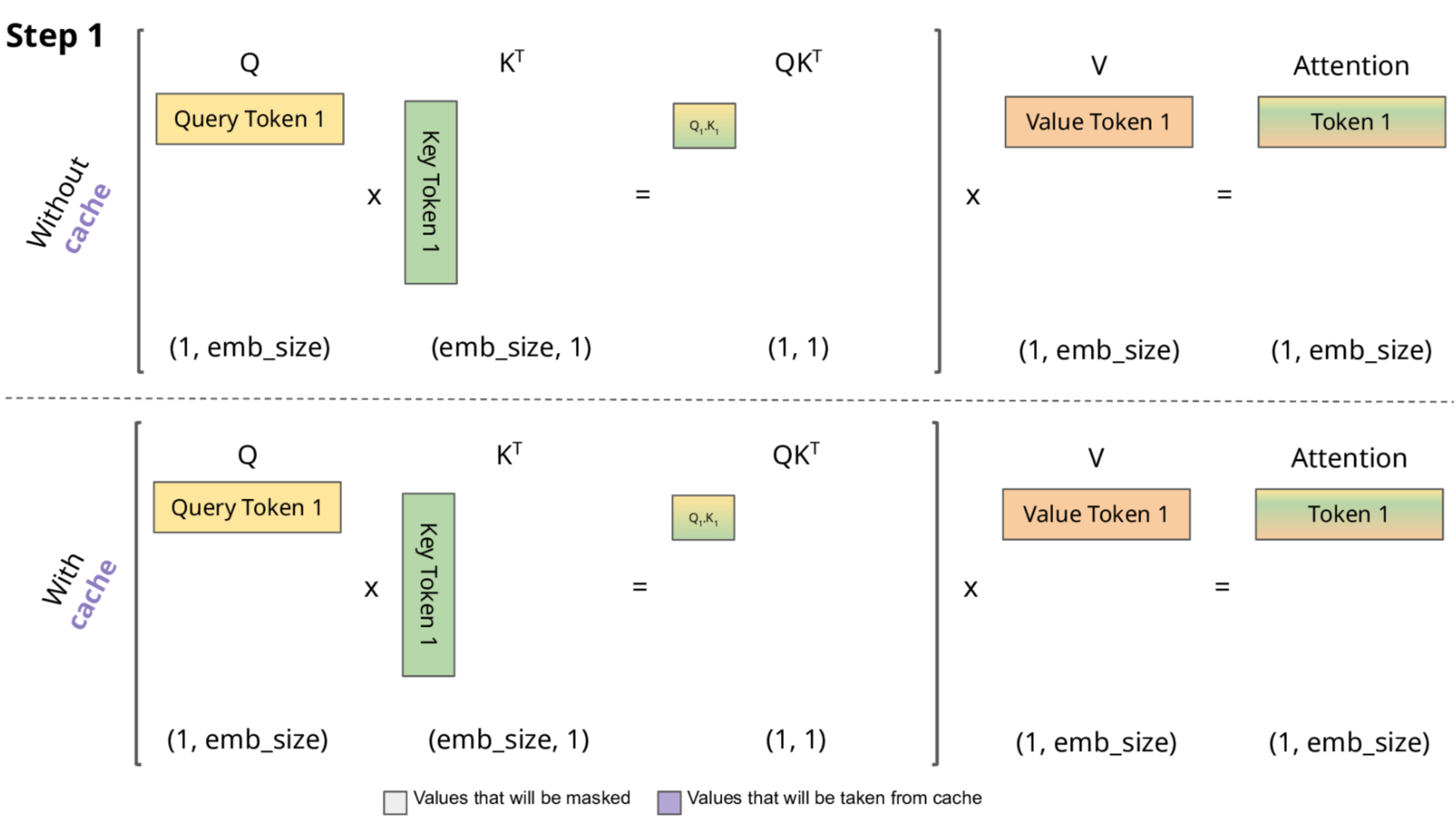
Let’s now illustrate the computations saved when using KV caching. As shown in the following Figure, given a first token:
- We compute the “Query Token 1” vector and “Key Token 1” vector, from which we can subsequently calculate the attention score $Q_1, K_1$.
- We then compute “Value Token 1” vector, and multiply with attention score $Q_1, K_1$ to produce output vector “Token 1”.
- Since this is the first token, there is no difference between using or not using KV caching.
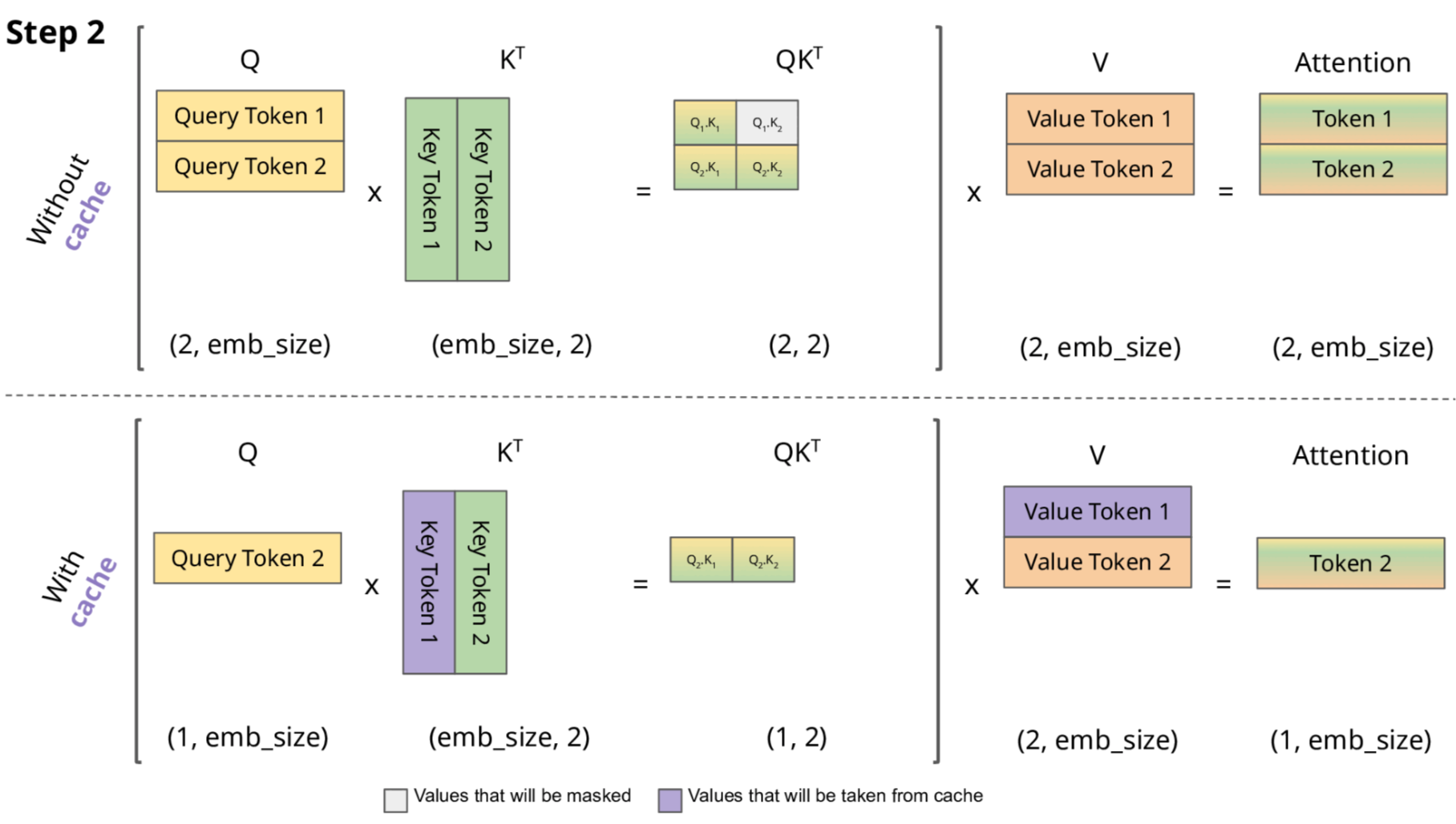
In the second time-step:
- We compute “Query Token 2” vector and “Key Token 2” vector. We then retrieve “Key Token 1” (which we had stored in cache). These allow us to calculate attention scores $Q_2, K_1$ and $Q_2, K_2$.
- Next, we compute “Value Token 2” vector, while retrieving “Value Token 1” from cache. Using the attention scores as a weighted sum over these two value vectors, allow us to compute the output vector “Token 2”.
Effects of KV Caching on Inference Time
To see the effects of KV caching, let’s run the following code
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "gpt2"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")
Here are the results on a A5000 GPU machine:
with KV caching: 6.244 +- 0.258 seconds
ithout KV caching: 21.098 +- 0.252 seconds
Written on July 16, 2023
