
GPT-3 Decoder Language Model
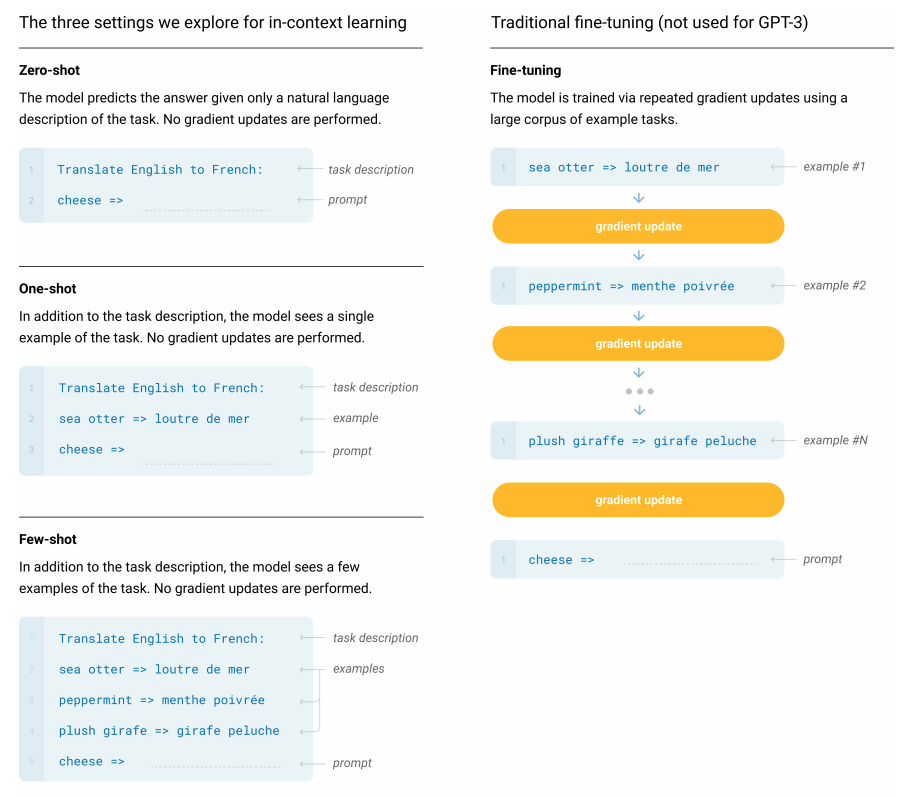
The GPT-3 language model was published in the paper “Language Models are Few-Shot Learners” in July 2020. GPT-3 is a 175 billion parameter pre-trained language model. In the GPT-3 paper, the authors did not perform fine-tuning (in any case, it will be very expensive to fine tune such a large model). Instead, the authors experimented with zero-shot, one-shot, and few-shot (few-shot is usually 10-100 examples) prompting. For all these experimental settings, there is no fine-tuning of model weights. Instead, the task description is simply provided in the input prompt to the model.
Model pre-training details and experiment setup
- The smallest GPT-3 model “GPT-3 Small” has 125M parameters (12 layers, 768 hidden dimension) which is the same size as GPT-1 and BERT-base. A larger model “GPT-3 XL” has 1.3B parameters (24 layers and 2048 dimensions) which is slightly smaller than the 1.5B GPT-2. The largest model “GPT-3” has 175B parameters (96 layers, 12288 hidden dimensions).
- All GPT-3 models use a context window of 2048 tokens, which is more than the 1024 used by GPT-2.
- The GPT-3 model architecture is similar to GPT-2, except that GPT-3 uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer (the self-attention computes a limited selection of similarity scores from a sequence rather than all possible pairs, resulting in a sparse attention matrix instead of a full matrix).
- GPT-3 pretrains on an in-house filtered version of Common Crawl (401 billion tokens, 570GB), WebText2, Books1, Books2, and Wikipedia, for a total of 499 billion tokens.
Few-shot evaluation results (no fine-tuning)
The GPT-3 paper conducted experiments in zero-shot, one-shot, and few-shot settings.
These are illustrated in the Figure below, which was extracted from the GPT-3 paper:
GPT-3 excels in generation style NLP tasks. However, GPT-3 is significantly worse than SOTA on classification tasks or tasks that require comparing two text snippets. More details follow:
- SuperGLUE: Results are significantly less than SOTA. Prompts for all tasks include 32 examples that were sampled randomly from the training set. GPT-3 averages (71.8), fine-tuned BERT-large (69.0), and fine-tuned SOTA (89.0). The authors commented that GPT-3 appears to be weak at tasks that involve comparing two sentences or snippets, e.g: whether a word is used in the same sense in two sentences, whether a sentence is a paraphrase of another, or whether one sentence implies another.
- Natural language inference (NLI a.k.a. entailment or RTE): Results are significantly less than SOTA. Evaluated on the RTE dataset of SuperGLUE, and the Adversarial natural language inference (ANLI) dataset.
- Reading comprehension (QA): Significantly less than SOTA. This includes the datasets of: CoQA, DROP, QuAC, SQuADv2, RACE.
- Common sense reasoning: GPT-3 only beats SOTA on the PhysicalQA (PIQA) dataset, while significantly lags behind SOTA in the ARC and OpenBookQA datasets.
- Winograd-style tasks: Significantly less than SOTA.
- Translation: GPT-3 beats SOTA when translating into English.
- Closed book QA: Beats SOTA on TriviaQA, but significantly less than SOTA on NaturalQSa nd WebQS.
- StoryCloze: Less than SOTA. This involves selecting the correct ending sentence for five sentence long stories.
- HellaSwag: Significantly less than SOTA. This involves picking the best ending to a story or set of instructions.
- LAMBADA: Significantly better than SOTA. The task involves predicting the last word of sentences.
Limitations of GPT-3:
The GPT-3 authors noted that the autoregressive language modeling approach of GPT-3 contributes to it being worse on tasks that benefits from bidirectionality, e.g.: fill-in-the blanks, text snippet comparison, passage reading and preforming QA to generate a short answer. They mentioned that a bidirectional model at the scale of GPT-3, or making bidirectional models work with few-shot learning would be a promising research direction.
The authors also noted that their current pretraining objective (decoder style of predicting the next token) weights every token equally and lacks a notion of what is most important to predict. They proposed that learning the objective function from humans and fine-tuning with reinforcement learning, will be promising future directions.
Finally, they also aknowledge that it is expensive to performance inference with models at the scale of GPT-3, and a future direction is distillation of large models down to a manageable size.
