
FLAN - Fine-Tuned Decoder Language Model
The FLAN model (Finetuned Language Net) from Google was introduced in the paper “Finetuned Language Models Are Zero-Shot Learners” published in September 2021. Basically shows that performing multitask fine-tuning improves zero-shot generalization to new tasks (i.e. tasks not included in fine-tuning).
The setup of FLAN is very similar to that of T0, a paper from Huggingface published a month later in October 2021 (both FLAN and T0 explored multitask fine-tuning). The main difference being that FLAN is based on LaMDA-PT (Google’s decoder-only language model), whereas T0 is based on T5 (Google’s encoder-decoder language model).
Important takeaways from the paper:
- FLAN is based on LaMDA-PT (137B model), a decoder-only language model which was pre-trained on (web docs, dialog data, Wikipedia) tokenized into 2.49T BPE tokens with 32K vocab using SentencePiece. Note that LaMDA-PT only has language model pretraining, vs. LaMDA which was finetuned for dialog.
- FLAN improves on the zero-shot performance of the base LaMDA-PT 137B model. Also outperforms GPT-3 zero-shot on 20 out of 25 datasets. But note that GPT-3 is just pre-trained and not fine-tuned.
- Interestingly, the benefits of finetuning is only with larger models. They finetuned on pre-trained models of different sizes: 422M, 2B, 8B, 68B, 137B. Finetuning hurts performance on heldout tasks for models 8B and smaller.
- Showed that given a finetuned FLAN model, doing few-shot in-context learning (i.e. few shot examples provided in prompt), further improves over zero-shot. The standard deviation of performance (i.e. deviation in performance when using different prompt wordings during inference) is also lower, thus few-shot reduces sensitivity to prompt engineering.
Datasets, training and evaluation
- Groups more than 60 NLP datasets into 12 clusters. Hold out each cluster for evaluation while finetuning on all other clusters. The grouping of tasks into clusters is shown below:
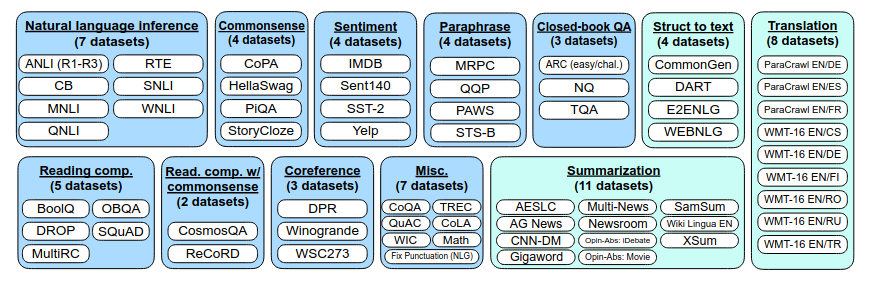
- For each dataset, manually compose 10 unique templates that use natural language to describe the task. The following Figure illustrates this:
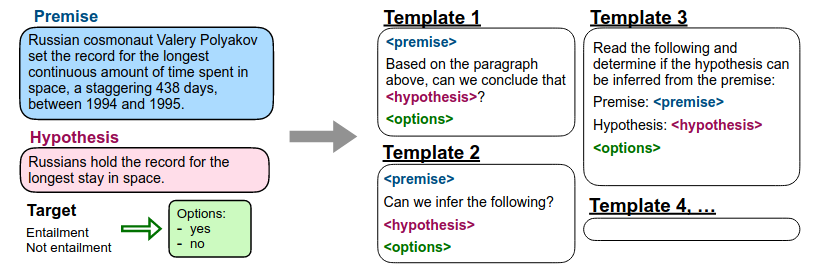
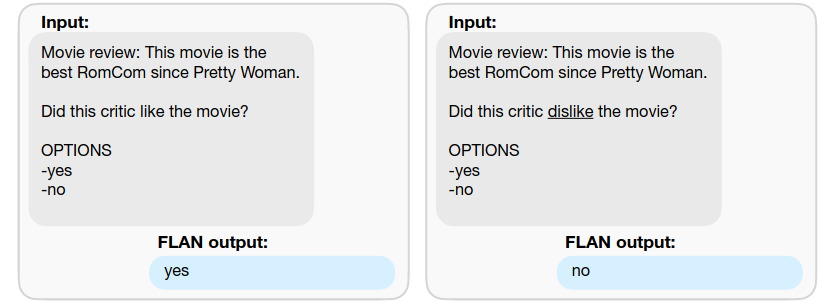
- During finetuning, each example in each dataset is formatted via a randomly selected template for that dataset. Some examples of FLAN prompts:
Written on February 1, 2023
