
ColBERT - Passage Search via Contextualized Late Interaction over BERT
ColBERT is a neural passage search model that was introduced in the paper “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT”, published in 2020.
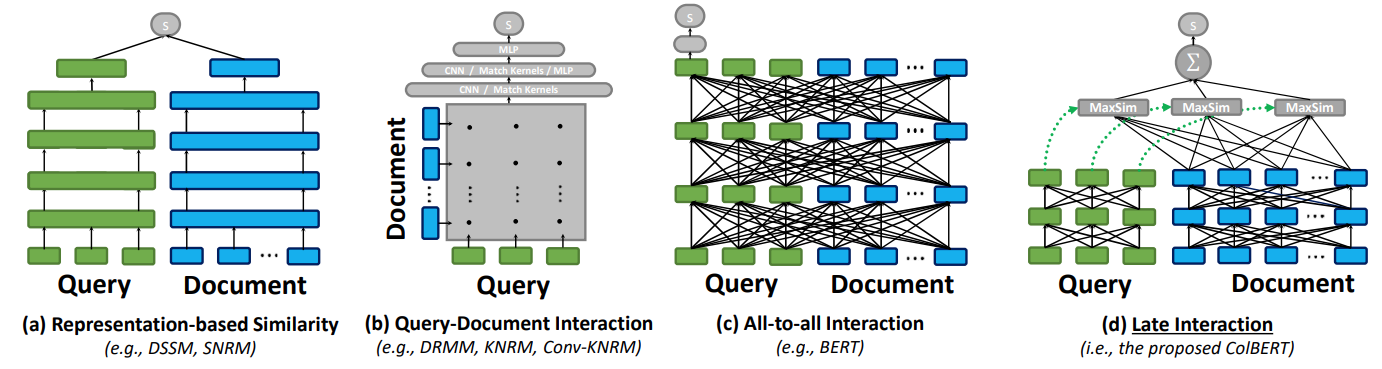
The different neural matching paradigms are in the above Figure:
- (a) representation-focused rankers: independently compute a query $q$ embedding (the single green box), and document $d$ embedding (the single blue box). Then estimate relevance of (q, d) as a single similarity score between the two vectors. We could precompute document representations offline.
- (b) interaction-focused rankers: once we get the per token embeddings (the small green and blue boxes) in both the query and document, then model their interactions.
- (c) interaction-focused rankers: more powerful version of the above, which models the interactions between words within as well as across q and d, e.g. in BERT (we named this cross-encoders). Feed the query–document pair through BERT and use an MLP on top of BERT’s
[CLS]output token to produce a relevance score We cannot precompute document representations offline. - (d) late interaction: the proposed ColBERT. This encodes documents offline. Every query embedding is compared to all document embeddings via a MaxSim operator to compute maximum similarity, and then summed up. This can leverage vector-similarity search indexes to quickly retreive top-k results.
The archiecture of ColBERT is as follows.
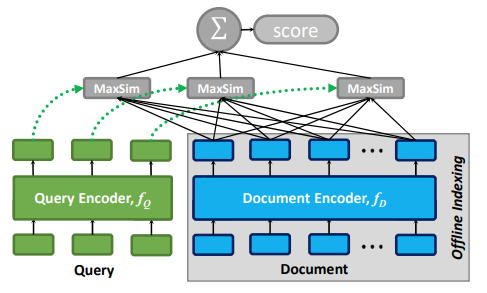
- Given query $q = q_0q_1 \ldots q_l$ and document $d = d_0d_1 \ldots d_n$, the authors compute the bags of embeddings $E_q$ and $E_d$ in the following manner, where the CNN is meant to produce an output embeddings that is smaller than the BERT embeddings:
- Then, the relevance score of $d$ to $q$ is calculated as follows. I.e. for each query (token) output embedding, find the most similar document (token) output embedding. Then sum up all these similarity scores:
- For fast top-K search (for each $i \in E_q$, retrieve top-K in $j \in E_d$), they use the FAISS library. They use an
IVFPQindex (inverted file with product quantization). This partitions the document embedding space into P=1000 cells based on k-means clustering. When searching for the top-k matches for a single query embedding, only the nearest ($p=10$) partitions are searched. Also, every embedding is divided into (s=16) sub-vectors (product quantization). This index conducts its similarity computations in this compressed domain.
Written on December 26, 2022
