
Chinchilla - A Compute Optimal Decoder Language Model
The Chinchilla model was described in “Training Compute-Optimal Large Language Models” published in March 2022. Introduced the Chinchilla model, an auto-regressive language model (70B model trained on 1.4T tokens) which performed better than GPT-3 (175B trained on 300B tokens) and Gopher (their prior work, an auto-regressive 280B model trained on 300B tokens).
This paper shows that for compute optimal training, the model size and number of training tokens should be scaled equally (for every doubling of model size, the number of training tokens should also be doubled). This debunks the usual practice of just scaling model size while keeping number of training tokens fixed.
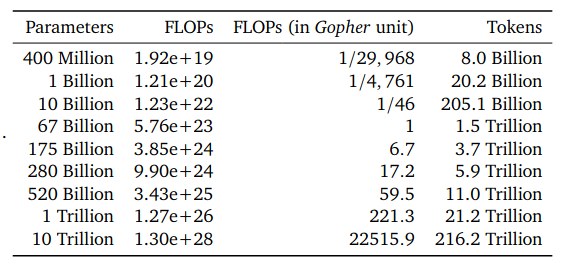
Recommended Model Size and Number of Training Tokens:
The authors also performed various experiments and recommended that AdamW performs better than Adam.
Model
- Chinchilla is an autoregressive decoder-only language model.
- Trains on a similar dataset as Gopher. Use SentencePiece.
- Has 70B parameters, 80 layers, 64 heads, 128 (key/value of each head), 8192 hidden dimension, batch size (starts at 1.5M, then double to 3M midway through training).
Evaluation
- Evaluates on language modeling (20 tasks), reading comprehension (3 tasks), QA (3 tasks), common sense (5 tasks), MMLU (massive multitask language understanding, 57 tasks), BIG-bench (62 tasks).
- On MMLU 5-shot experiments, Chinchilla (67.6%) significantly outperforms GPT-3 (43.9%) and Gopher (60.0%). Also outperforms GPT-3 and Gopher in most other tasks.
