
How was ChatGPT Trained?
ChatGPT was built on top of the InstructGPT paper “Training language models to follow instructions with human feedback” published in March 2022.
InstructGPT itself, is based off an earlier work from OpenAI titled “Learning to summarize from human feedback” published in September 2020. We dive into this paper first, before describing InstructGPT.
Learning to summarize from human feedback
The aim of this paper is to is to leverage human preferences, reward modeling, and reinforcement learning (RL) to improve abstractive summarization.
Approach
As motivation, the authors first note that the usual practice of fine-tuning pretrained models for downstream tasks (such as abstractive summarization) might be misaligned with human preferences:
- Specifically, during fine-tuning, the model maximize the likelihood of examples (human written text) as the training objective. However, this misaligns against evaluation metrics such as ROUGE or qualitative human evaluations.
- The reason for the misalignment is because the maximum likelihood objective treats all words equally and does not distinguish between important vs unimportant errors.
Overview
To address the misalignment, the authors proposed the approach illustrated in the following Figure.
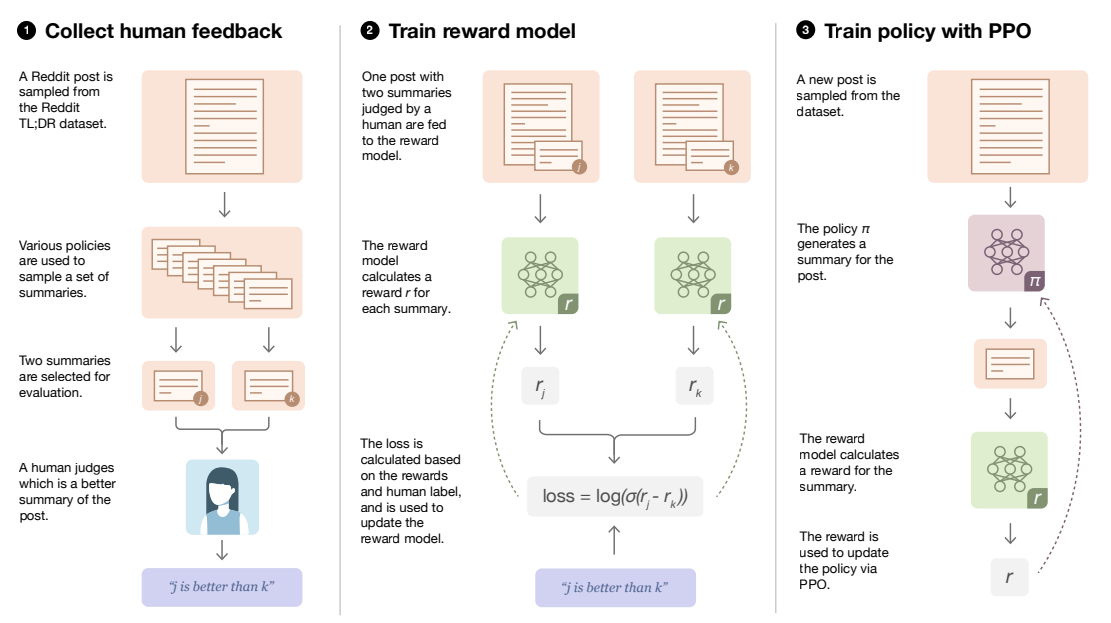
- First, collect a dataset of human preferences between pairs of summaries, then train a supervised reward model (RM) to predict the human-preferred summary. The summarization dataset is based off reddit.com posts with their associated summaries of posts written by the original poster. A filtered dataset of 123K posts with summaries (with maximum length 48 tokens long) is used as the TL;DR dataset referred to in the Figure. The authors prefer this curated dataset over the more commonly used CNN/DM dataset because very strong performance can be obtained on the CNN/DM by simply extracting the first-3 sentences as the summary.
- Train a generation policy via reinforcement learning (RL) to maximize the score given by the RM. The generation policy generates a token of text at each “time step”. Once the entire summary has been generated, the policy is updated using the PPO algorithm based on the RM “reward” given to the entire generated summary.
- Then gather more human data using samples from the updated policy, and repeat the above process.
We now detail the different models used in the approach.
Pretrained models
The authors used the 1.3B and 6.7B GPT-3 as their pretrained models in their experiments.
Supervised fine-tuning (SFT)
Next, they fine-tune the above pretrained models on their TL;DR dataset (given original post, predict associated summary) to produce $\pi^{\text{SFT}}$ models.
Reward model (RM)
Starting from the above $\pi^{\text{SFT}}$ models, add a randomly initialized linear head that outputs a scalar value. Given a post $x$, the linear head predicts which summary $y \in {y_0, y_1}$ is judged as better by a human. Let the human preferred summary be $y_i$, then the RM loss is: \(\text{loss}(r_\theta) = - \mathbb{E}_{(x,y_0,y_1,i) \sim D}[\text{log}(\sigma(r_\theta(x,y_i) - r_\theta(x,y_{1-i})))]\)
- Where $r_\theta(x,y)$ is the scalar output of RM for post $x$ and summary $y$, and $D$ is the dataset of human pairwise judgements. They normalize their RM output such that reference summaries achieve a mean score of 0.
- Minimizing the above RM loss is equivalent to maximizing $r_\theta(x,y_i) - r_\theta(x,y_{1-i})$, i.e. the score of the preferred summary $y_i$.
- To expand on the above loss function, recall the definitions of $\mathbb{E}(X)$ and $\mathbb{E}(g(X))$:
- $\mathbb{E}(X) = \sum_{x}x f_X(x) = \sum_{x} x P(X=x)$.
- $\mathbb{E}(g(X)) = \sum_{x}g(x)f_{X}(x) = \sum_{x} g(x)P(X=x)$
- Thus, we can rewrite the above loss as the following, where $g(X) = \text{log}(\sigma(\cdot))$ and each sample $(x,y_0,y_1,i)$ occurs with equal probability: \(\text{loss}(r_\theta) = - \frac{1}{|D|} \sum_{(x,y_0,y_1,i) \in D} \text{log}(\sigma(r_\theta(x,y_i) - r_\theta(x,y_{1-i})))\)
Human feedback policies
We want to learn a policy $\pi_{\phi}^{\text{RL}}$ that generates higher quality outpus as judged by humans. We treat the scalar output of the reward model as a reward for the entire summary that we maximize with the PPO algorithm, where each time step is a BPE token.
Note that that RM only gives rewards for entire summaries and not at intermediate time steps. Each Reinforcement learning episode terminates when the policy outputs the EOS token.
We initialize the $\pi_{\phi}^{\text{RL}}$ policy model as the $\pi^{\text{SFT}}$ model. We then maximize the following reward $R(x,y)$ with PPO: \(R(x,y) = r_{\theta}(x,y) - \beta \text{log}[\pi_{\phi}^{\text{RL}}(y|x) / \pi^{\text{SFT}}(y|x)]\)
Evaluation
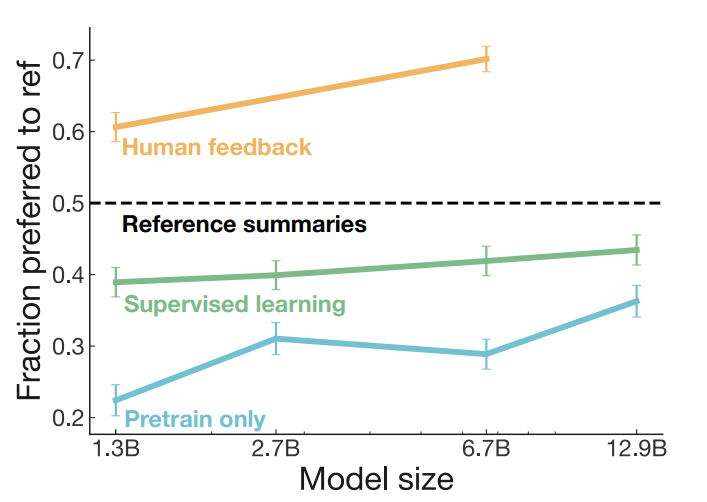
Experiments were conducted to measure the quality of summaries generated by the $\pi_{\phi}^{\text{RL}}$ policy model, the $\pi^{\text{SFT}}$ model, and the pre-trained models. Quality is quantified as the percentage of model generated summaries that humans prefer vs the original human written reference summaries. As shown in the Figure below, the $\pi_{\phi}^{\text{RL}}$ model trained with human feedback significantly outperforms the $\pi^{\text{SFT}}$ baselines. Specifically, the 1.3B $\pi_{\phi}^{\text{RL}}$ model already significantly outperforms the 12.9G $\pi^{\text{SFT}}$ model).
InstructGPT: Reinforcement Learning Fine-Tuned Decoder Language Model
InstructGPT aims to leverage human preferences, reward modeling (RM), and reinforcement learning (RL) to improve GPT-3 models for a wide variety of textual tasks. InstructGPT follows the fine-tuning, RM, and RL approach taken in OpenAI’s prior work “Learning to summarize from human feedback”.
The main difference is that the prior work focused on a single task (abstractive summarization), while InstructGPT leveraged a variety of user prompts to align GPT-3 responses to human preferences. This work trained 3 sizes of InstructGPT models: 1.3B, 6B, and 175B parameters. The task distribution of the prompts are: generation (45%), open QA (12%), brainstorming (11%), chat (8%), rewrite (6%), summarization (4%), classification (3%), closed QA, extract, and others.
Approach
The following Figure extracted from the InstructGPT paper illustrates the approach:
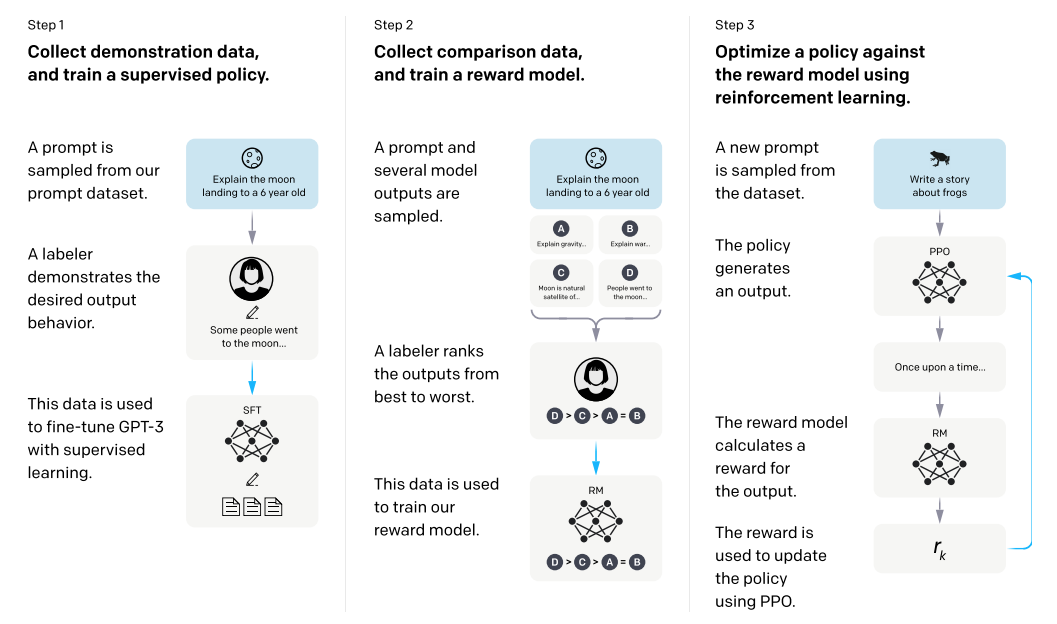
Step 1: Supervised fine-tuning (SFT)
- This step performs supervised fine-tuning on the pretrained GPT models.
- First, select a set of 13K prompts, using a mixture of prompts submitted to the OpenAI API, and some labeler written prompts. Then collect human written demonstrations (from a team of 40 human contractors) of the desired output on the 13K prompts.
- Starting from pre-trained GPT-3 models, the collected prompts are used to fine-tune GPT-3 to obtain supervised fine-tuned (SFT) models $\pi^{\text{SFT}}$. They also call this a supervised policy (using reinforcement learning terminology).
Step 2: Reward modeling (RM)
- This step trains a reward model (RM). Given a prompt and response, output a scalar reward to predict which output human labelers would prefer.
- First, select a set of 33K prompts, using a mixture of prompts submitted to the OpenAI API, and some labeler written prompts. For each prompt, use GPT models to generate up to $K = 9$ responses. This produces $K \choose 2$ pairwise comparisons for each prompt. Then collect human rankings or preferences on these pairwise comparisons to trai a reward model (RM) as follows.
- Take the above SFT models, remove the unembedding layer (the layer which takes the final hidden representation, does a dot product with the token embeddings, to output softmax probabilities on the word to predict), and replace with a projection layer that outputs a scalar value, that indicates the quality (reward) of the input prompt reponse.
- All the $K \choose 2$ pairwise comparisons for each prompt are included as part of a training batch. The RM loss function is as follows:
\(\text{loss}(\theta) = -\frac{1}{K \choose 2} \mathbb{E}_{(x,y_w,y_l) \sim D}[\text{log}(\sigma(r_{\theta}(x,y_w) - r_{\theta}(x,y_l)))]\)
- Where $r_{\theta}(x,y)$ is the scalar output of the RM for prompt $x$ and response $y$ with parameters $\theta$. $y_w$ is the preferred response, compared to $y_l$. $D$ is the dataset of human comparisons.
Step 3: Optimize Response Generation using Reinforcement Learning
- This step fine-tunes $\pi^{\text{SFT}}$ models to produce $\pi_{\phi}^{\text{RL}}$ (learned RL policy) models. The fine-tuning aims to produce prompt reponses that maximize the scalar reward (as given by the RM model), using the PPO algorithm.
- Using a set of 31K training prompts, maximize the following objective $\text{objective}(\phi)$ in RL training: \(\mathbb{E}_{(x,y) \sim D_{\pi_{\phi}^{\text{RL}}}} [r_{\theta}(x,y) - \beta \text{ log}(\pi_{\phi}^{\text{RL}}(y|x) / \pi^{\text{SFT}}(y|x))] +\\ \gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} [\text{log}(\pi_{\phi}^{\text{RL}}(x))]\)
- In the above:
- $\pi_{\phi}^{\text{RL}}$ is the learned RL policy, initialized from the supervised fine-tuned model $\pi^{\text{SFT}}$.
- Dividing by $\pi^{\text{SFT}}(y|x)$ aims to ensure that $\pi^{\text{SFT}}$ does not deviate too much from $\pi^{\text{SFT}}(y|x)$.
- $D_{\text{pretrain}}$ is the pretraining data distribution. InstructGPT refers to the above as the PPO-ptx model (where pretraining gradients are mixed into the PPO gradients). For purely “PPO” models, $\gamma$ is set to 0.
- Here, the $y$ is generated by the current RL policy.
Evaluation
Labelers rate the quality of model outputs on a set of held-out prompts. The main evaluation results are shown in the following Figure, extracted from the InstructGPT paper:
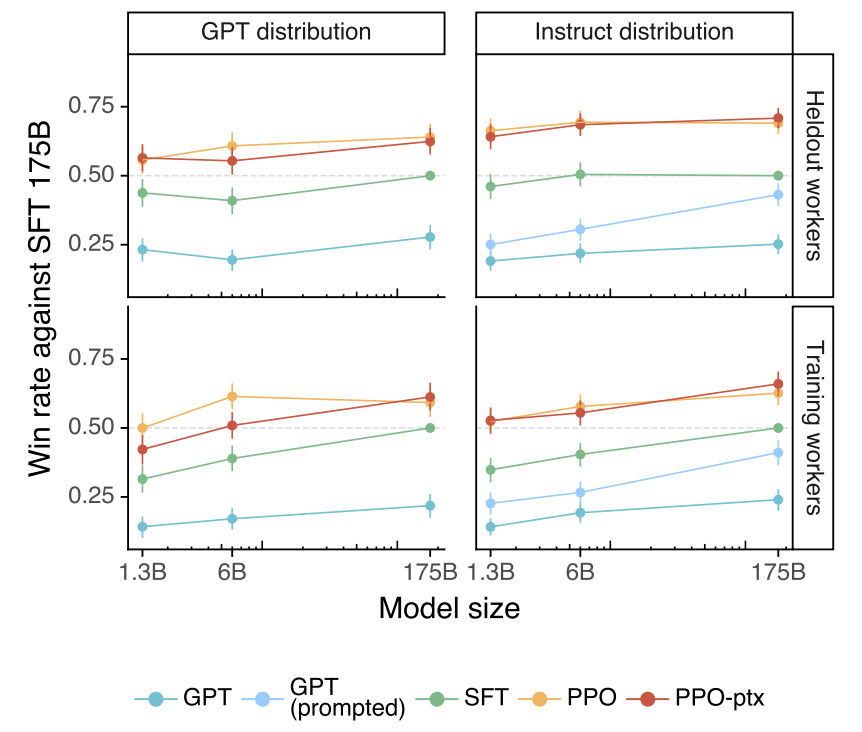
- The “GPT distribution” graphs on the left refers to results on prompts submitted to GPT models on OpenAI’s API. The “Instruct distribution” graphs on the right refers to results on prompts submitted to InstructGPT models on the API. The upper 2 graphs reflect results from held-out labelers. The bottom 2 graphs reflect results from training labelers.
- There is a sizeable performance gap between SFT and PPO. However, I note that the SFT models are trained on 13K prompts, whereas the RM models are trained a larger set of 33K prompts, and the RL models are trained on 31K prompts. So the question is would training SFT on significantly more than 13K prompts close the gap w.r.t. PPO models.
