
BART Encoder-Decoder Language Model
BART is a language model from Meta, described in the paper “BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension”, published in October 2019. It is most similar to the T5 model, which is also an encoder-decoder Transformer.
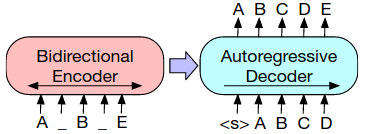
BART is a sequence to sequence model, with a bidirectional encoder over corrupted text and a left-to-right auto-regressive decoder. The base model has 6 layers (each in encoder and decoder). Large model has 12 layers each with 406M parameters. Each layer of decoder additionally performs cross-attention over the final layer of the encoder.
Differences with BERT, GPT, T5
- BERT: This is an encoder-only Transformer where documents are encoded bidirectionally, and pretraining is done with a MLM objective where random tokens are replaced with masks, and masked tokens are predicted independently.
- GPT: This is a decoder-only Transformer where tokens are predicted auto-regressively. Words can only be conditioned on leftward contexts, so it cannot learn bidirectional interactions.
- T5: Similar to BART, T5 is an encoder-decoder Transformer. But in T5, only the masked text spans are predicted, whereas BART predicts the complete output. Another difference is when fine-tuning, T5 predicts the output auto-regressively in the decoder. Whereas BART feeds the final hidden representation of its decoder into a classification layer. More details below.
Pre-Training and Fine-Tuning
| Pre-Training | Fine-Tuning |
|---|---|
 |
 |
- Pre-training. First, text is corrupted with a noising function. Then, a sequence-to-sequence model is learned to reconstruct the original text. That is, the corrupted document is encoded with a bidirectional model, then the likelihood of the original document is calculated with an auto-regressive decoder (we optimize the negative log likelihood of the original document). This is similar to the T5 model, but BART explores the following text corruption options:
- Token masking: Following BERT, random tokens are sampled and replaced with [MASK].
- Token deletion: Random tokens are deleted from the input text.
- Text infilling: A number of text spans are sampled (average length 3). Each span is replaced with a single [MASK] token. Text infilling is inspired by SpanBERT, but SpanBERT replaces each span with a sequence of [MASK] tokens of exactly the same length.
- Sentence permutation: Sentences are shuffled in random order.
- Document rotation: A token is chosen uniformly at random, and the document is rotated so that it begins with that token.
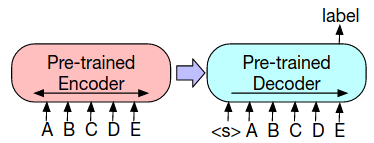
- Fine-tuning: The uncorrupted text is input to both the encoder and decoder, and we use representations from the final hidden state or layer of the decoder.
- Sequence classification tasks: the same input is fed into the encoder and decoder, and the final hidden state (i.e. from last layer) of the final decoder token is fed into a new multi-class linear classifier.
- Token classification tasks: feed the texts into both the encoder and decoder, and use hidden states (of last layer) of decoder as a representation of each token. This representation is used to perform token classification.
- Sequence generation: For instance, abstractive QA and summarization. Input text is fed to encoder, and decoder generates outputs auto-regressively.
Final BART model
- The BART-large model has 406M parameters (12 layers each of encoder and decoder), hidden size 1024, batch size 8000, and was trained for 500K steps.
- Tokenization using the byte-pair-encoding of GPT-2.
- For text corruption, it used a combination of text infilling (mask 30% of tokens, spans of average 3 tokens in length) and permutation of all sentences.
- Same pre-training data as the Roberta model (160GB of news, books, stories, and web text).
Written on February 6, 2023
